Comentábamos en un artículo anterior una de las aplicaciones de la Estadística en el ámbito de la Seguridad, cual era el análisis y la gestión de tiempos de evacuación. En ese caso planteábamos el estudio de los condicionantes de la propia evacuación y nos centrábamos en la minimización del tiempo empleado, por medio de estudios de simulación. En esta aportación vamos a presentar el uso de la Estadística para obtener información relevante en términos de la Seguridad de un evento, y en un tiempo anterior a que éste se produzca.
Si en el artículo anterior nos referíamos a acontecimientos muy graves como acciones terroristas o de elementos aislados contra la seguridad de grandes masas de gente, ahora vamos a considerar el caso de que es una masa de personas la que, una vez convocada, puede alterar la seguridad general. Hablamos, por ejemplo, de los prolegómenos de un partido de fútbol , de un concierto multitudinario, o de cualquier otra manifestación masiva, que se convoca actualmente por medio de Redes Sociales. En este tipo de situaciones es evidente que la falta de información previa sobre tales concentraciones puede alterar el orden público, máxime cuando algunas se realizan justamente con ese fin.
El Análisis de Contenido, también conocido en la literatura con otras denominaciones como Análisis de Datos Textuales y referido al análisis web más particularmente como Análisis de Sentimiento (Sentiment Analysis en inglés) o «minería de opinión», engloba a un conjunto de técnicas estadísticas que tratan con información de textos y, como decimos, por ejemplo en las webs. Se trata de identificar y extraer información de fuentes de texto diversas, por ejemplo Facebook, Twitter, Instagram, etc., en las que se detecte de forma automática las connotaciones de estado de ánimo sobre un tema.
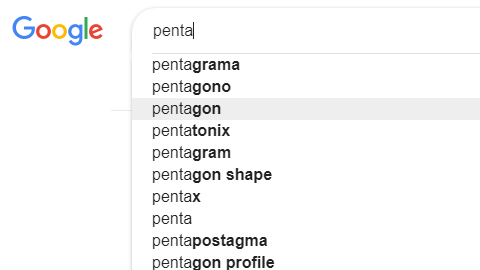
En esta área de trabajo es de especial importancia el análisis de palabras concretas referidas a algún asunto de interés, y la mayor o menor coocurrencia de palabras. Un ejemplo del primer caso es la detección automática de palabras con la misma raíz lingüística por medio de los denominados N-gramas, que no son más que secuencias de N letras. En un problema relativo a Seguridad en espectáculos públicos podría interesar analizar la presencia en la web de ciertos vocablos, por ejemplo el N-grama «revent». Este N-grama se puede referir a «reventa» (de entradas) o «reventar» (reventamos, reventando, etc.) el espectáculo. Como observamos, no solo será interesante analizar cambios en la frecuencia de aparición del N-grama en un período y contexto concreto, sino también coocurrencias con otras palabras. Por simple que parezca este enfoque, en la actualidad hay muchos temas de Criminología y Seguridad que lo tienen como base, entre los que citaremos aplicaciones en la detección de plagios y la red Echelon. Huelga decir que el procesador de búsquedas de Google, que utilizamos a diario, está basado en la predicción (secuencia de letras más probable) sobre el N-grama que se va escribiendo en el campo de búsqueda.
El análisis de coocurrencias es, si cabe, más interesante. En efecto, la aparición conjunta de dos o más palabras en un texto puede indicar diferentes connotaciones en términos de estados de ánimo del autor. Propiamente el Análisis de Sentimiento es el conjunto de técnicas que tratan de analizar la actitud (enfado, tristeza, felicidad, etc.) vertida en un documento. Aquí, las asociaciones se pueden establecer reconociendo grupos de palabras que aparecen juntas, mediante el análisis clúster, o palabras que aparecen solo asociadas a determinados sentimientos, por ejemplo de ira, entre otras situaciones. Siguiendo con nuestro ejemplo en una situación de Seguridad preventiva, podríamos plantearnos detectar la secuencia «quedada en la puerta» (o quedada-puerta si prescindimos de artículos y preposiciones) en textos en los que aparezca el N-grama «revent», para a continuación analizar el sentimiento en el texto concreto. En este ejemplo, detectar un conjunto reciente de textos de connotaciones negativas, debería marcarnos una alerta en la preparación del dispositivo de seguridad.
En la actualidad hay mucha investigación científica dedicada a estas materias, si bien ya hay desarrollo de software específico para tratar estos problemas entre los que citaremos SAS Entrepise Miner y IBM SPSS Modeler (anterior Clementine), algunos desarrollos de Google Cloud para Sentiment Analysis y WEKA, este último de libre uso. El software mencionado no es específico para materia de Seguridad, si bien recientemente también se están produciendo publicaciones centradas en este campo aunque en solo revistas especializadas de Estadística o Computación. Estamos seguros de que más pronto que tarde estos avances serán, también, de uso común en Seguridad, gracias a la capacidad de previsión y de evaluación de riesgos que proporcionan estas técnicas a los profesionales de este ámbito.
Pedro Antonio García López
Catedrático de Métodos Estadísticos en Criminología
Decano de la Facultad de Ciencias del Trabajo
Universidad de Granada